Blog/Product
How to accelerate LLaMA 3 fine-tuning with FP8
October 22, 2024
This tutorial was authored by Anjali Shah, Sudhakar Singh, and Santosh Bhavani from NVIDIA, and formatted by the Latitude.sh team.
LLaMA 3 introduces several improvements over LLaMA 2. Trained on a significantly larger dataset (15T tokens vs. 2.2T tokens), the latest iteration of Meta’s large language model supports a longer context length of up to 8K tokens compared to its predecessor.
In this tutorial, you will learn how to fine-tune LLaMA 3 with FP8 precision using Hugging Face Accelerate, PEFT, and Transformer Engine.
For deploying and managing the necessary infrastructure, we'll use the Latitude.sh bare metal platform, which offers automated solutions for AI workloads and predefined templates.
Summary
Introduction to Transformer Engine
Transformer Engine (TE) is a library that accelerates Transformer model training on NVIDIA GPUs. It supports FP8 precision on Hopper and Ada GPUs, enhancing performance while maintaining accuracy during training and inference.
TE provides optimized building blocks for popular Transformer architectures and an automatic mixed precision API compatible with major deep learning frameworks.
Setting up the environment
To launch a JupyterLab notebook on the Latitude.sh platform, follow these steps:
1. Access the Latitude.sh dashboard, and navigate to "Serverless" in the sidebar
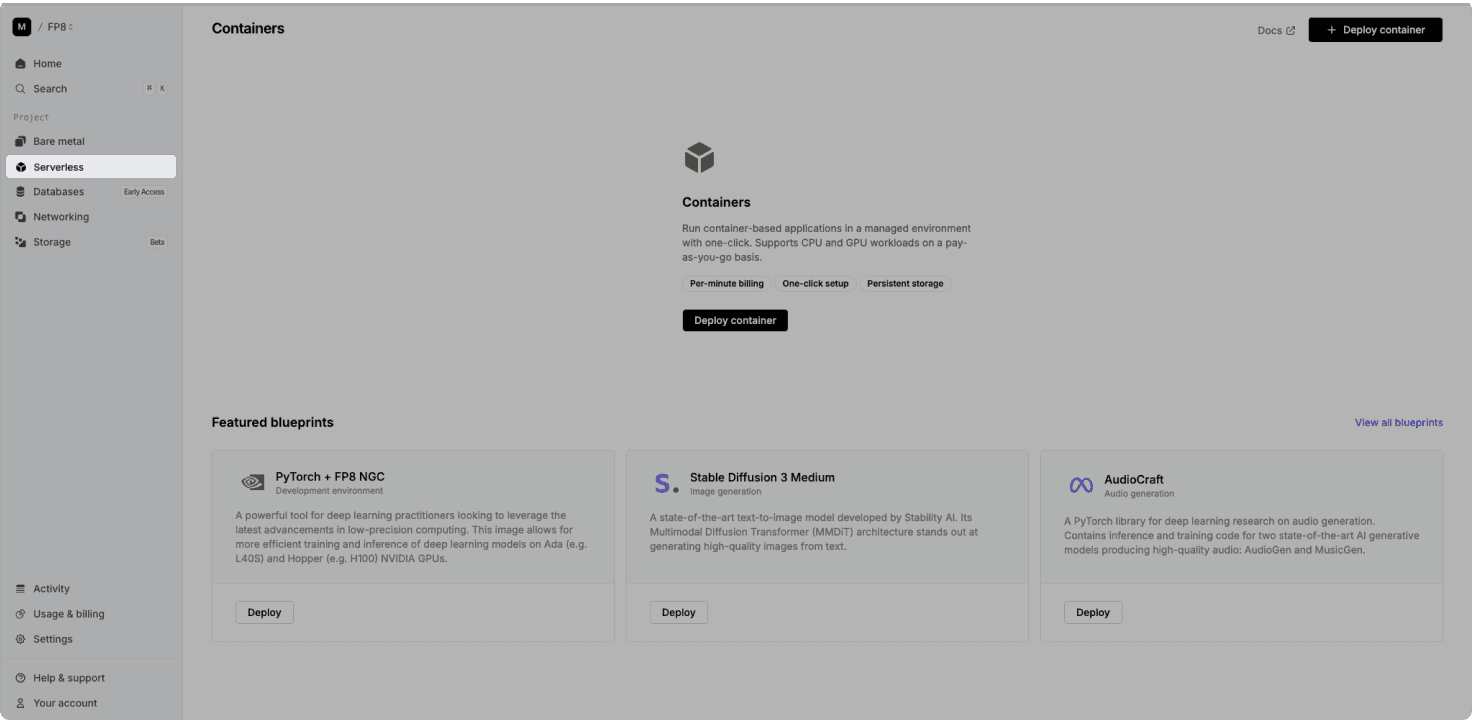
2. Select the blueprint
Latitude.sh allows you to deploy containers using blueprints. You can either select an existing blueprint or create a new one tailored to your needs.
To make it easy to use all the required libraries and ensure the best performance and compatibility with NVIDIA GPUs, we'll use the pre-built PyTorch + NGC FP8 blueprint. This launches an NVIDIA DL container for PyTorch which includes the latest optimized versions of PyTorch and Transformer Engine.
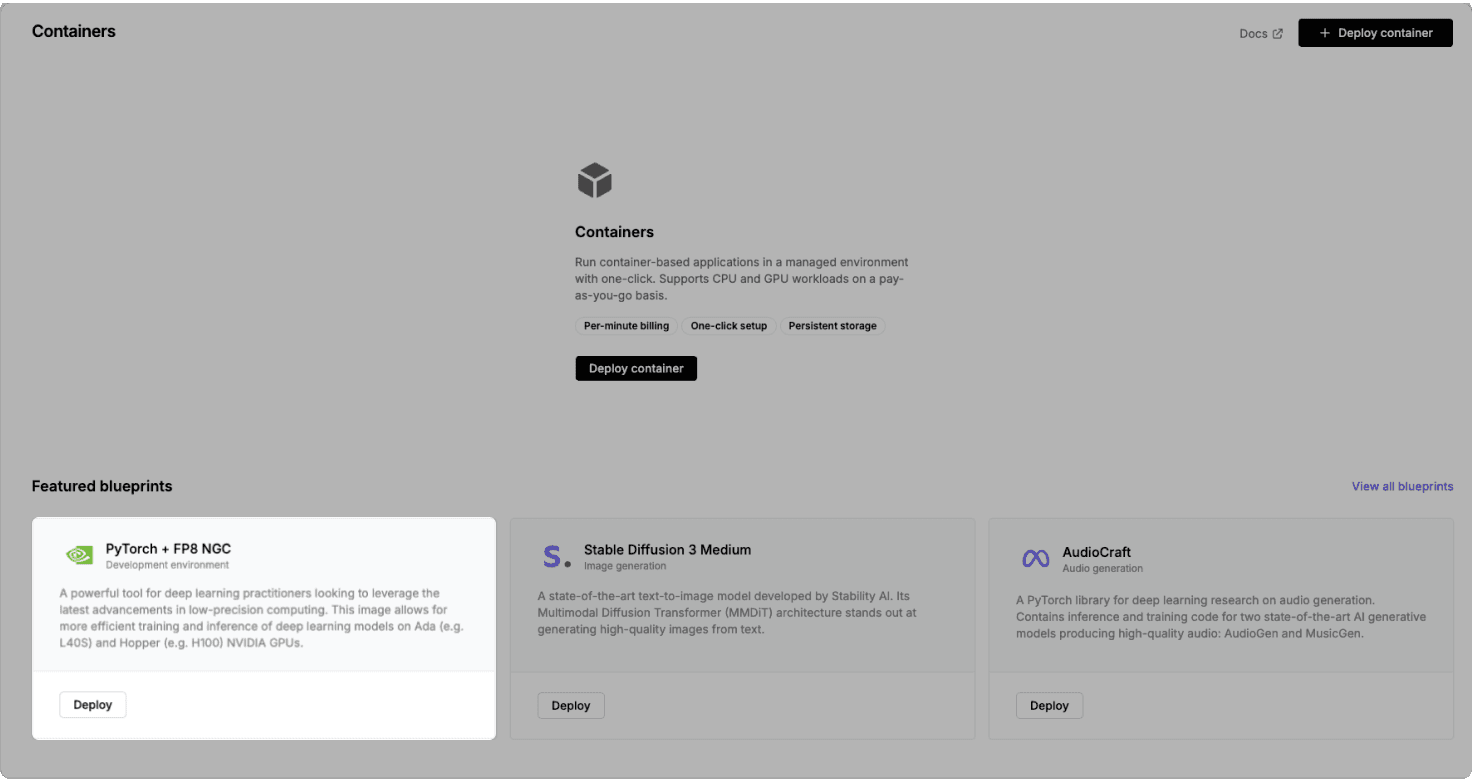
To learn more about the container visit NVIDIA’s NGC Catalog.
3. Deploy the container
Once you click Deploy, you are ready to launch your container. This will provision the hardware and install the necessary software as specified in the blueprint.
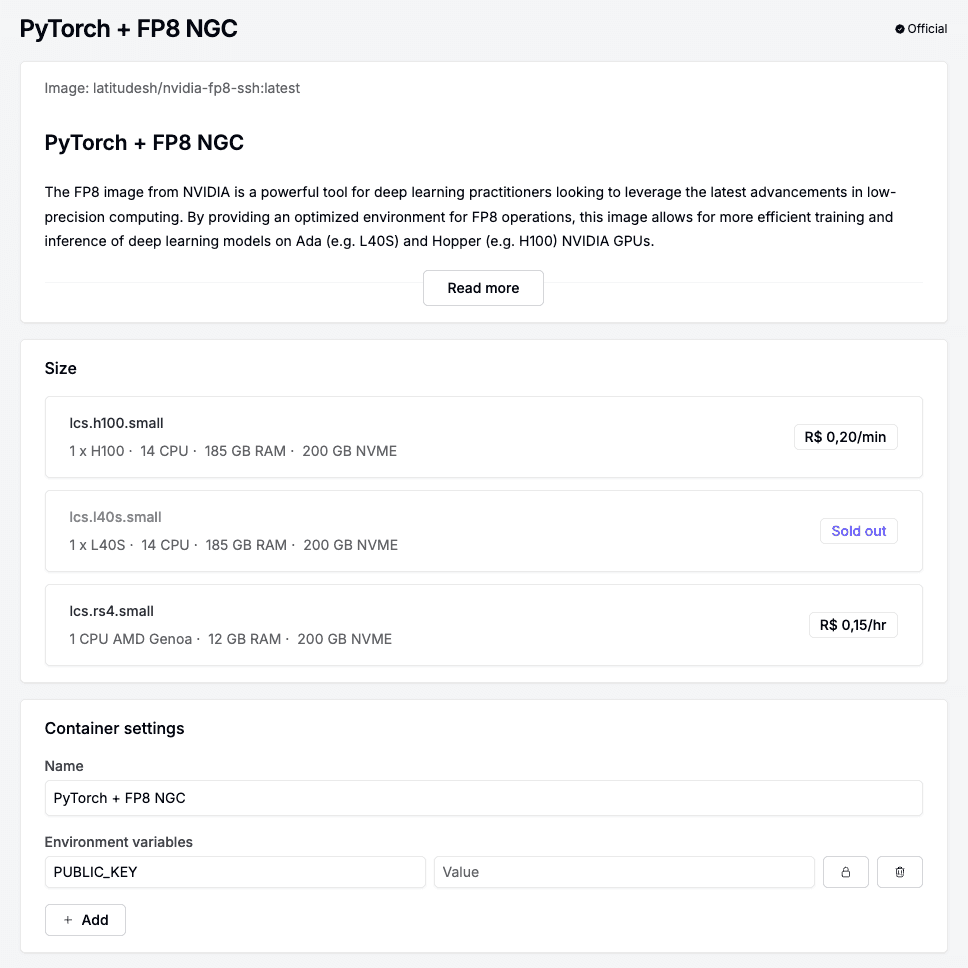
Size: FP8 is currently supported only on Hopper and Ada GPUs. Ensure you select a compatible GPU architecture, such as H100 or L40S.
Environment variables: In order to SSH into your instance, add your SSH public key in the environment variable for PUBLIC_KEY. Refer to Latitude.sh docs for more details.
4. SSH into the instance
Once your instance is deployed, copy the IP address, open a terminal and enter this command:
bash
ssh -L 8888:localhost:8888 root@<ip_addr>
This creates an SSH tunnel and mapping port 8888 in your remote machine with your host machine port 8888. We do this to enable access to JupyterLab from our local machine's browser.
5. Launch JupyterLab Navigate to the directory where you want to work and start JupyterLab by running:
bash
pip install protobuf==3.20.*
export PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python
jupyter lab
This command will start the JupyterLab server. You can now navigate to your browser and copy the URL from your terminal replacing ‘hostname’ with ‘localhost’ or IP address of your host server.
Fine-tuning LLaMa 3 with FP8
Now that your environment is set, let's explore how to accelerate LLaMA 3 finetuning using NVIDIA's Transformer Engine (TE) by following the steps outlined in the Jupyter notebook available here.
Note: This notebook has dependencies on utils.py and te_llama.py python scripts that should be downloaded along with the notebook.
Step 1: Import necessary libraries
First, let's import the required libraries:
To get started, ensure you have access to the necessary libraries and tools. Install the required packages, including `transformers`, `accelerate`, and `peft`:
python
!pip install transformers accelerate peft datasets huggingface_hub ipywidgets
Step 2: Load the LLaMA Model and Tokenizer
We will load the LLaMA model and its tokenizer from the Hugging Face model hub by providing Access Token:
python
hyperparams.hf_access_token = ""
Step 3: Replace Transformer layers with TE layers
To leverage NVIDIA's Transformer Engine, we need to replace the standard transformer layers in the LLaMA model with TE layers. Here's how you can do it:
python
for i, layer in enumerate(model.model.layers):
model.model.layers[i] = TransformerLayer(layer)
Step 4: Performance evaluation
After setting up and running your model with TE, it's essential to evaluate its performance.
Conclusion
In this tutorial, we showed how to speed up the Hugging Face LLaMA model using NVIDIA’s Transformer Engine. By swapping standard transformer layers with TE layers, we achieved significant performance boosts in training and inference, making it ideal for large language models.
Feel free to experiment further with different configurations and datasets to fully harness the power of NVIDIA's Transformer Engine. Happy coding!